Agenta
Agenta empowers teams to build reliable AI apps together with integrated LLMOps tools.
AI tool Details
Explore More
Alternatives
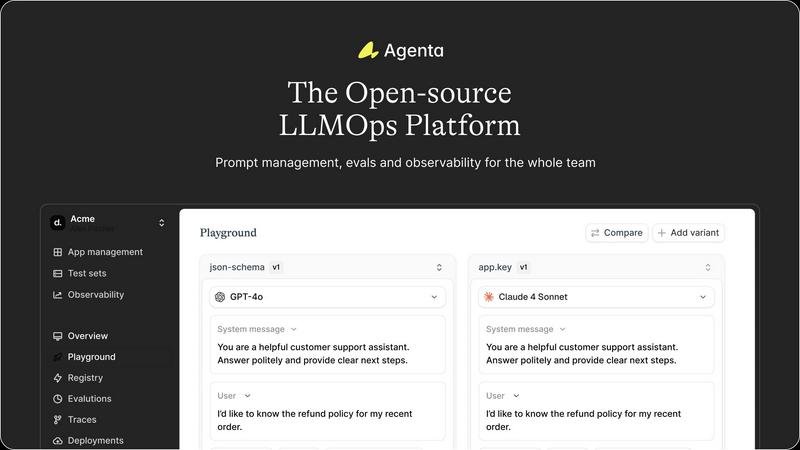
About Agenta
Agenta is the transformative, open-source LLMOps platform designed to empower AI teams to build and ship reliable, high-performance LLM applications with confidence. It directly addresses the core chaos of modern AI development, where unpredictable models meet scattered workflows, siloed teams, and a lack of validation. Agenta provides the single source of truth your entire team needs, from developers and engineers to product managers and domain experts. It centralizes the entire LLM development lifecycle into one cohesive platform, enabling structured collaboration and replacing guesswork with evidence. The core value proposition is clear: move from fragmented, risky processes to a unified workflow where you can experiment intelligently, evaluate systematically, and observe everything in production. This empowers teams to iterate faster, validate every change, and debug issues precisely, ultimately transforming how reliable AI products are built and scaled. By integrating prompt management, evaluation, and observability, Agenta is the essential infrastructure for any team committed to shipping trustworthy AI.
Features
Unified Playground & Versioning
Agenta provides a centralized playground where your team can iterate on prompts and compare different models side-by-side in real-time. Every change is automatically versioned, creating a complete history of your experiments. This model-agnostic approach prevents vendor lock-in and ensures you can always use the best model for the task. Found an error in production? You can instantly save it to a test set and debug it directly within the playground, closing the feedback loop rapidly.
Systematic Evaluation Framework
Replace guesswork with evidence using Agenta's powerful evaluation system. Create a systematic process to run experiments, track results, and validate every single change before deployment. The platform supports any evaluator you need, including LLM-as-a-judge, custom code, or built-in metrics. Crucially, you can evaluate the full trace of an agent's reasoning, not just the final output, and seamlessly integrate human feedback from domain experts into your evaluation workflow.
Production Observability & Debugging
Gain complete visibility into your AI systems with comprehensive observability. Agenta traces every request, allowing you to pinpoint exact failure points when things go wrong. You and your team can annotate these traces collaboratively or gather direct feedback from end-users. With a single click, turn any problematic trace into a test case. Live, online evaluations continuously monitor performance and proactively detect regressions, ensuring your application remains reliable.
Structured Team Collaboration
Break down silos and bring product managers, domain experts, and developers into one unified workflow. Agenta provides a safe, intuitive UI for non-technical experts to edit prompts and run experiments without touching code. Everyone can participate in running evaluations and comparing results, fostering data-driven decisions. The platform offers full parity between its API and UI, ensuring seamless integration of programmatic and manual workflows into a single hub of truth.
Use Cases
Accelerating Agent Development
Teams building complex AI agents with multi-step reasoning can use Agenta to experiment with different reasoning chains, evaluate each intermediate step for accuracy, and debug logic failures in the trace. This transforms a black-box process into a transparent, iterative one, significantly reducing time-to-market for reliable agentic applications.
Centralizing Enterprise Prompt Management
For organizations where prompts are scattered across emails, Slack, and documents, Agenta serves as the single source of truth. It allows centralized version control, structured A/B testing of prompt variations, and controlled rollouts, ensuring consistency, governance, and optimal performance across all LLM-powered features.
Implementing Rigorous QA for LLM Features
Product and QA teams can establish a robust validation pipeline using Agenta. They can create persistent test sets from real user interactions, run automated evaluations against every new prompt or model version, and integrate human-in-the-loop reviews from domain experts to catch nuanced failures before they reach production.
Streamlining Cross-Functional AI Projects
When projects require input from developers, product managers, and subject matter experts, Agenta's collaborative environment is essential. It enables non-coders to safely tweak prompts and run evaluations, while developers manage the infrastructure, all working from the same platform with shared visibility, eliminating miscommunication and accelerating iteration.
Pricing
Agenta is an open-source platform, and the core software is free to use. You can download, self-host, and modify it without any licensing fees. For detailed information on enterprise support, managed cloud offerings, or additional services, please visit the official Agenta website or use the "Book a demo" link to speak with their team directly.
Frequently Asked Questions
Is Agenta really open-source?
Yes, Agenta is a fully open-source platform. You can dive into the code on GitHub, contribute to the project, and self-host the entire platform. This ensures transparency, avoids vendor lock-in, and allows for deep customization to fit your specific infrastructure and workflow needs.
How does Agenta integrate with existing frameworks?
Agenta is designed for seamless integration. It works with popular LLM frameworks like LangChain and LlamaIndex, and is model-agnostic, supporting APIs from OpenAI, Anthropic, Cohere, and open-source models. You can integrate it into your existing stack without a major overhaul.
Can non-technical team members use Agenta effectively?
Absolutely. A core design principle of Agenta is to empower the entire team. It provides an intuitive web UI that allows product managers and domain experts to edit prompts, run experiments, and evaluate results without writing any code, bridging the gap between technical development and business expertise.
How does Agenta help with debugging in production?
Agenta provides full observability by tracing every LLM call and user request. When an error occurs, you can examine the complete trace to see the exact input, model calls, intermediate steps, and final output. You can annotate these traces, share them with your team, and instantly convert any problematic trace into a test case for future validation.
Similar to Agenta
Caesura
A macOS menu-bar app that reminds you to drink water, stretch, rest your eyes, and breathe for anyone working long hours at a desk.
PrompTessor
Stop guessing with AI and start commanding it with PrompTessor, the all-in-one workspace to generate, optimize, and master every prompt for flawless.