Friendli Engine
About Friendli Engine
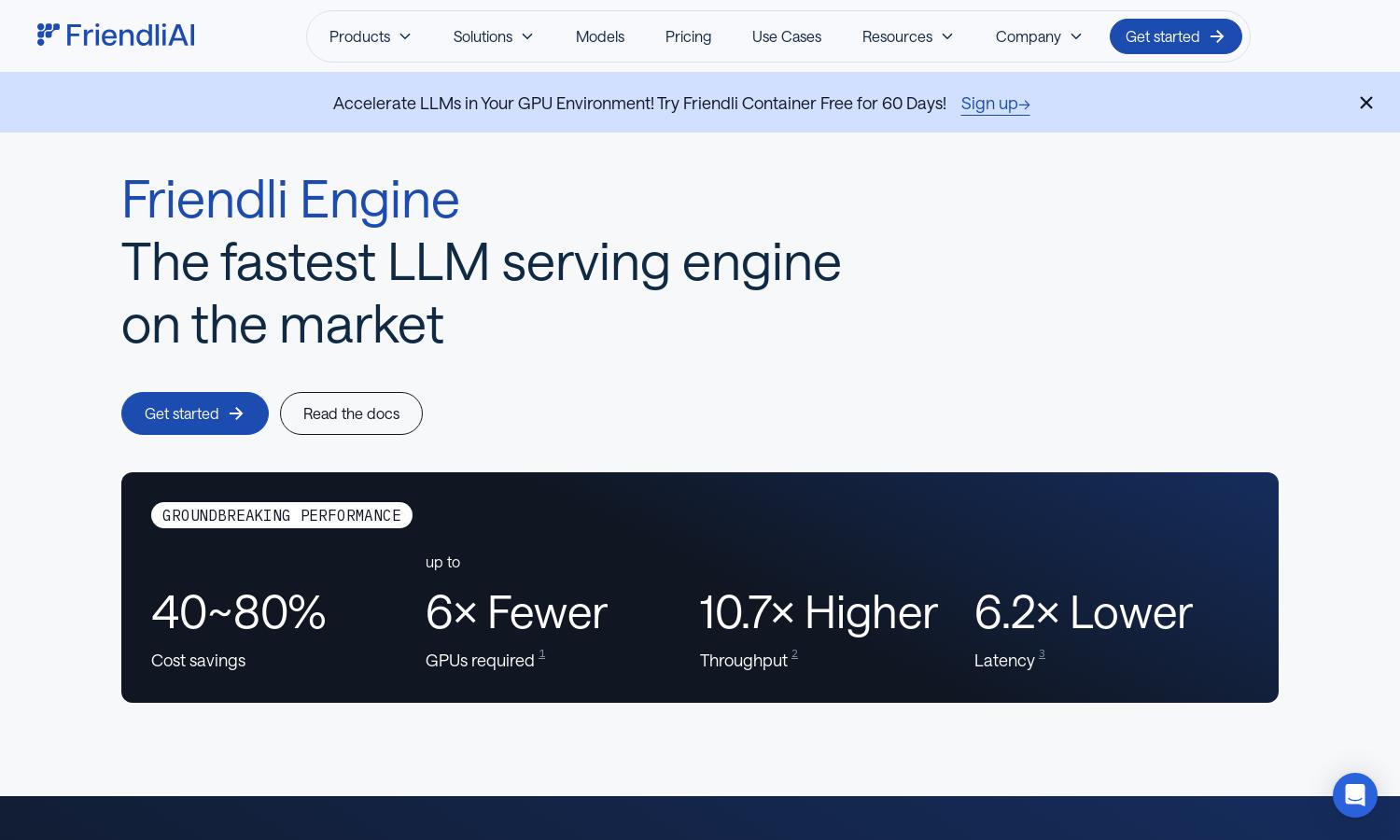
Friendli Engine is designed for developers and businesses looking to optimize LLM deployment. Its groundbreaking features, like Iteration Batching and speculative decoding, boost performance and reduce costs, meeting the needs of modern applications. With Friendli Engine, users can achieve faster result delivery while maintaining flexibility.
Friendli Engine offers flexible pricing plans catering to various needs. The basic plan provides essential features, while higher tiers unlock advanced optimizations and support for multiple models. Upgrading enhances user experience by delivering better performance, cost savings, and streamlined workflows essential for competitive AI solutions.
Friendli Engine boasts an intuitive user interface designed for efficiency. Its streamlined layout facilitates easy navigation through features like model deployment and performance metrics, ensuring users can quickly access tools. The design also accommodates customization options, making it user-friendly and visually appealing for all skill levels.
How Friendli Engine works
Users begin with onboarding, where they can learn about Friendli Engine's capabilities. After creating an account, they navigate to the dashboard, selecting models for deployment. Utilizing features like Iteration Batching, users can optimize performance while tracking their results in real time. This straightforward process highlights efficiency and performance-enhancing technologies.
Key Features for Friendli Engine
Iteration Batching
Iteration Batching is a unique feature of Friendli Engine, drastically improving LLM inference throughput. This innovative technology allows users to handle multiple generation requests concurrently, optimizing resource utilization and minimizing latency while maintaining high-quality outputs, enhancing overall user experience.
Multi-LoRA Support
Friendli Engine enables Multi-LoRA support on fewer GPUs, allowing users to run multiple models simultaneously. This feature simplifies LLM customization and enhances efficiency, making it accessible for developers to fine-tune and deploy diverse generative AI applications without excessive hardware requirements.
Speculative Decoding
Speculative Decoding is a powerful optimization in Friendli Engine that accelerates LLM inference by predicting future tokens. This approach minimizes response times without compromising output accuracy, providing users with a competitive edge in speed and efficiency in generative AI tasks.
You may also like: